River Flood based on GloFAS Discharge Data#
This tutorial will guide through the process of computing flood foodprints from GloFAS river discharge data and using these footprints in CLIMADA impact calculations.
Executing this tutorial requires access to the Copernicus Data Store (CDS) and the input data for the flood footprint pipeline. Please have a look at the documentation of the GloFAS River Flood module and follow the instructions in its “Preparation” section before continuing.
The first step is setting up the “static” data required for the river flood model.
The setup_all() function will download the flood hazard maps, the FLOPROS flood protection database, and the pre-computed Gumbel distribution fit parameters.
This might take a while.
from climada.util import log_level
from climada_petals.hazard.rf_glofas import setup_all
with log_level("DEBUG", "climada_petals"):
setup_all()
/home/roo/miniforge3/envs/climada_flood/lib/python3.9/site-packages/dask/dataframe/_pyarrow_compat.py:17: FutureWarning: Minimal version of pyarrow will soon be increased to 14.0.1. You are using 12.0.1. Please consider upgrading.
warnings.warn(
2024-02-29 14:54:26,872 - climada_petals.hazard.rf_glofas.setup - DEBUG - Rewriting flood hazard maps to NetCDF files
2024-02-29 14:54:26,873 - climada_petals.hazard.rf_glofas.setup - DEBUG - Merging flood hazard maps into single dataset
2024-02-29 14:58:21,780 - climada_petals.hazard.rf_glofas.setup - DEBUG - Downloading FLOPROS database
2024-02-29 14:58:22,371 - climada_petals.hazard.rf_glofas.setup - DEBUG - Downloading Gumbel fit parameters
from climada_petals.hazard.rf_glofas import RiverFloodInundation
countries = ["Germany", "Switzerland", "Austria"]
rf = RiverFloodInundation()
rf.download_forecast(
countries=countries,
forecast_date="2021-07-10",
preprocess=lambda x: x.max(dim="step"),
system_version="operational", # Version mislabeled
)
ds_flood = rf.compute()
ds_flood
/home/roo/miniforge3/envs/climada_flood/lib/python3.9/site-packages/xarray/core/dataset.py:282: UserWarning: The specified chunks separate the stored chunks along dimension "latitude" starting at index 1377. This could degrade performance. Instead, consider rechunking after loading.
warnings.warn(
/home/roo/miniforge3/envs/climada_flood/lib/python3.9/site-packages/xarray/core/dataset.py:282: UserWarning: The specified chunks separate the stored chunks along dimension "longitude" starting at index 3480. This could degrade performance. Instead, consider rechunking after loading.
warnings.warn(
2024-02-29 14:58:26,019 - climada_petals.hazard.rf_glofas.cds_glofas_downloader - INFO - Skipping request for file '/home/roo/climada/data/cds-download/240229-145826-83e84eba8992a4a4d5f8af0a923e2458.grib' because it already exists
/home/roo/miniforge3/envs/climada_flood/lib/python3.9/site-packages/dask/array/routines.py:325: PerformanceWarning: Increasing number of chunks by factor of 50
intermediate = blockwise(
<xarray.Dataset>
Dimensions: (number: 50, time: 1, longitude: 1356, latitude: 1128)
Coordinates:
* number (number) int64 1 2 3 4 5 6 7 8 ... 44 45 46 47 48 49 50
* time (time) datetime64[ns] 2021-07-10
surface float64 ...
step timedelta64[ns] ...
* longitude (longitude) float64 5.854 5.863 5.871 ... 17.14 17.15
* latitude (latitude) float64 55.15 55.14 55.13 ... 45.76 45.75
Data variables:
flood_depth (latitude, longitude, time, number) float32 dask.array<chunksize=(762, 162, 1, 50), meta=np.ndarray>
flood_depth_flopros (latitude, longitude, time, number) float32 dask.array<chunksize=(762, 162, 1, 50), meta=np.ndarray>The returned dataset contains two variables, flood_depth and flood_depth_flopros which indicate the flood footprints without and with FLOPROS protection levels considered, respectively.
Notice that intermediate data is stored in a cache directory by default, but the returned flood data is not.
You can use save_file() to store it.
The cache directory will be deleted as soon as the RiverFloodInundation object is.
from climada_petals.hazard.rf_glofas import save_file
save_file(ds_flood, "flood-2021-07-10.nc")
To use the data within CLIMADA we will have to “translate” it into a Hazard object.
We provide a helper function for that: climada_petals.hazard.rf_glofas.rf_glofas.hazard_series_from_dataset().
Here we have to specify the variable to be read as hazard intensity (we choose the one without FLOPROS protection levels) and the dimension of the dataset that indicates the “event” dimension of the Hazard object.
If the dataset contained more dimensions than event_dim, latitude and longitude, the function hazard_series_from_dataset would return a pandas Series of Hazard objects indexed with these additional dimensions.
We will see this later.
Notice that storing data and reading it from a file might in some cases be faster than loading the data directly into a Hazard object, because the latter requires some potentially costly transpositions of the underlying data structures.
from climada_petals.hazard.rf_glofas import hazard_series_from_dataset
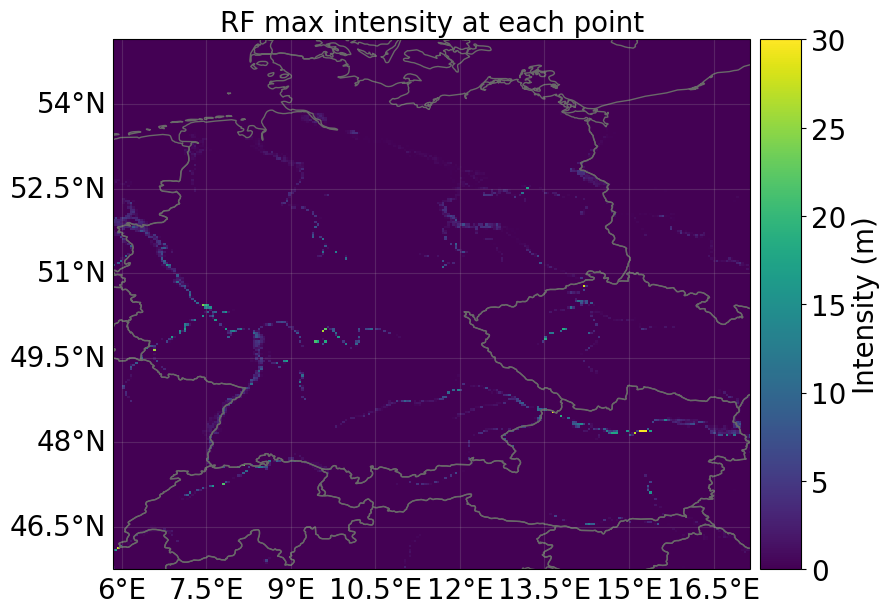
hazard = hazard_series_from_dataset(
ds_flood, intensity="flood_depth", event_dim="number"
)[0]
hazard.plot_intensity(event=0)
2024-02-29 14:59:26,406 - climada.hazard.base - WARNING - Failed to read values of 'number' as dates. Hazard.event_name will be empty strings
/tmp/ipykernel_41108/360336388.py:3: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
hazard = hazard_series_from_dataset(
<GeoAxes: title={'center': 'RF max intensity at each point'}>
Exposure and Vulnerability#
When looking at flood warnings and protection we typically want to determine how many people might be affected from floods or lose their homes.
We therefore use data on population distribution as exposure.
To that end, we create a LitPop exposure with the pop mode for the countries of interest.
Being affected by a flood can be considered a binary classification (yes/no), therefore we use a simple step function with a relatively low threshold of 0.2 m.
Notice that we set the impact function identifier to "RF" because this is the hazard type identifier of RiverFlood.
from climada.entity import LitPop
from climada.entity import ImpactFunc, ImpactFuncSet
# Create a population exposure
exposure = LitPop.from_population(["Germany", "Switzerland", "Austria"])
exposure.gdf["impf_RF"] = 1
# Create a impact function for being affected by flooding
impf_affected = ImpactFunc.from_step_impf(
intensity=(0.0, 0.2, 100.0), impf_id=1, haz_type="RF"
)
impf_set_affected = ImpactFuncSet([impf_affected])
2024-02-29 14:59:53,885 - climada.entity.exposures.litpop.litpop - INFO -
LitPop: Init Exposure for country: DEU (276)...
2024-02-29 14:59:53,935 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:53,936 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:53,956 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:53,957 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:53,982 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:53,983 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:54,006 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:54,007 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:54,031 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:54,032 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:54,058 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:54,059 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:54,084 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:54,085 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:54,104 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:54,105 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:54,134 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:54,135 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:54,151 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:54,151 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:54,185 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:54,186 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,052 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,053 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,119 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,120 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,194 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,195 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,257 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,258 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,339 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,340 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,411 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,412 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,478 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,479 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,541 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,542 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,614 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,615 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:56,685 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2024-02-29 14:59:56,687 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2024-02-29 14:59:58,417 - climada.entity.exposures.litpop.litpop - INFO -
LitPop: Init Exposure for country: CHE (756)...
2024-02-29 15:00:00,409 - climada.entity.exposures.litpop.litpop - INFO -
LitPop: Init Exposure for country: AUT (40)...
2024-02-29 15:00:01,222 - climada.entity.exposures.base - INFO - Hazard type not set in impf_
2024-02-29 15:00:01,223 - climada.entity.exposures.base - INFO - category_id not set.
2024-02-29 15:00:01,224 - climada.entity.exposures.base - INFO - cover not set.
2024-02-29 15:00:01,224 - climada.entity.exposures.base - INFO - deductible not set.
2024-02-29 15:00:01,225 - climada.entity.exposures.base - INFO - centr_ not set.
Impact Calculation#
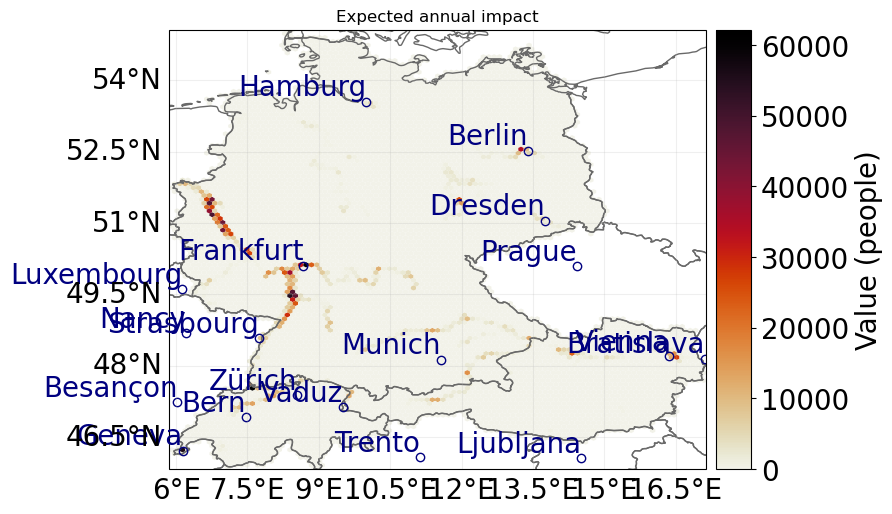
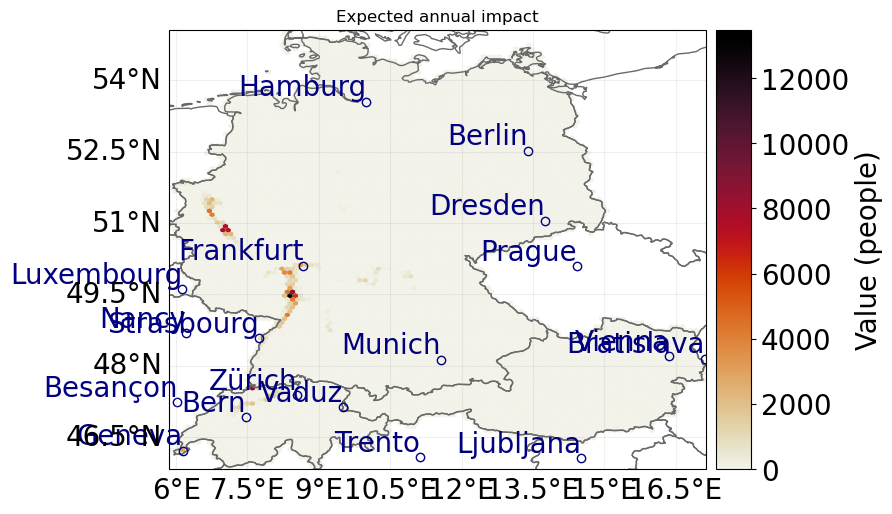
We simply plug everything together and calculate the impact. Afterwards, we plot the average impact for 14 July 2021.
The averaging function takes the frequency parameter of the hazard into account.
By default, all hazard events have a frequency of 1.
This may result in unexpected values for average impacts.
We therefore divide the frequency by the number of events before plotting.
import numpy as np
from climada.engine import ImpactCalc
hazard.frequency = hazard.frequency / hazard.size
impact = ImpactCalc(exposure, impf_set_affected, hazard).impact()
impact.plot_hexbin_eai_exposure(gridsize=100, lw=0)
2024-02-29 15:00:01,268 - climada.entity.exposures.base - INFO - Matching 876313 exposures with 1529568 centroids.
2024-02-29 15:00:01,281 - climada.util.coordinates - INFO - No exact centroid match found. Reprojecting coordinates to nearest neighbor closer than the threshold = 100
2024-02-29 15:00:03,547 - climada.engine.impact_calc - INFO - Calculating impact for 2606616 assets (>0) and 50 events.
<GeoAxes: title={'center': 'Expected annual impact'}>
FLOPROS Database Protection Standards#
So far, we ignored any protection standards, likely overestimating the impact of events.
The FLOPROS database provides information on river flood protection standards.
It is a supplement to the publication by P. Scussolini et al.: “FLOPROS: an evolving global database of flood protection standards”
It was automatically loaded when you called setup_all().
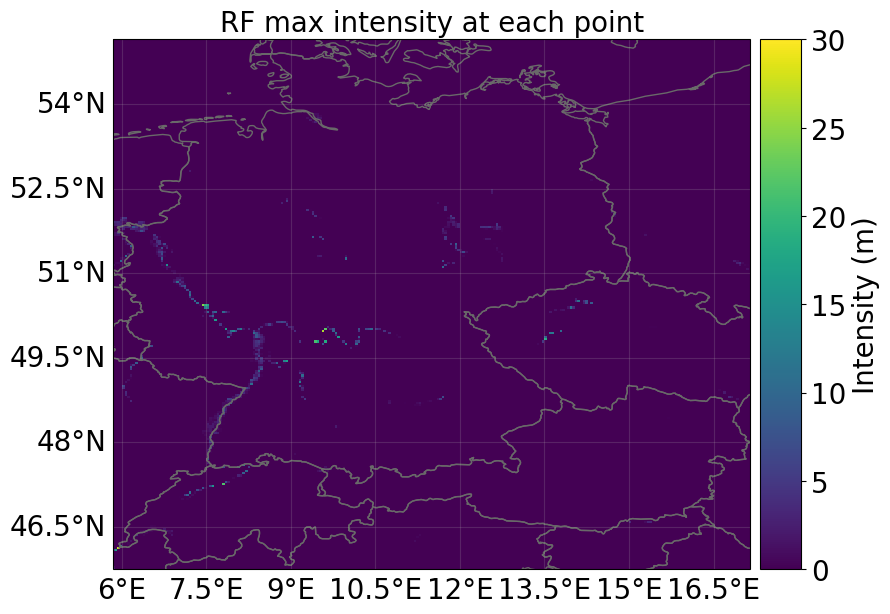
Let’s compare the hazard and corresponding impacts when considering the FLOPROS protection standards!
hazard_flopros = hazard_series_from_dataset(
ds_flood, intensity="flood_depth_flopros", event_dim="number"
)[0]
hazard_flopros.plot_intensity(event=0)
2024-02-29 15:00:09,411 - climada.hazard.base - WARNING - Failed to read values of 'number' as dates. Hazard.event_name will be empty strings
/tmp/ipykernel_41108/1832447213.py:1: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
hazard_flopros = hazard_series_from_dataset(
<GeoAxes: title={'center': 'RF max intensity at each point'}>
hazard_flopros.frequency = hazard_flopros.frequency / hazard_flopros.size
impact_flopros = ImpactCalc(exposure, impf_set_affected, hazard_flopros).impact()
impact_flopros.plot_hexbin_eai_exposure(gridsize=100, lw=0)
2024-02-29 15:00:37,496 - climada.entity.exposures.base - INFO - Exposures matching centroids already found for RF
2024-02-29 15:00:37,497 - climada.entity.exposures.base - INFO - Existing centroids will be overwritten for RF
2024-02-29 15:00:37,498 - climada.entity.exposures.base - INFO - Matching 876313 exposures with 1529568 centroids.
2024-02-29 15:00:37,514 - climada.util.coordinates - INFO - No exact centroid match found. Reprojecting coordinates to nearest neighbor closer than the threshold = 100
2024-02-29 15:00:39,504 - climada.engine.impact_calc - INFO - Calculating impact for 2606616 assets (>0) and 50 events.
<GeoAxes: title={'center': 'Expected annual impact'}>
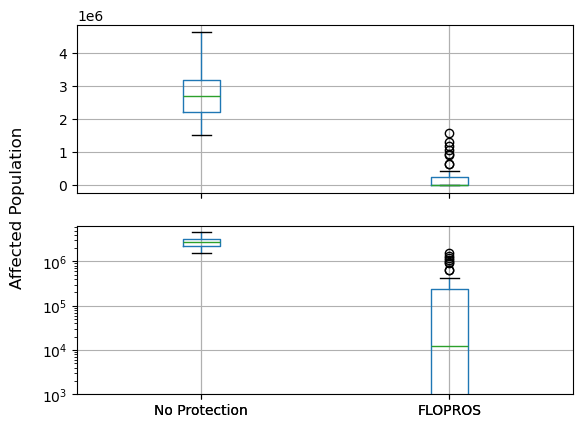
import pandas as pd
import matplotlib.pyplot as plt
df_impact = pd.DataFrame.from_dict(
data={"No Protection": impact.at_event, "FLOPROS": impact_flopros.at_event}
)
fig, axes = plt.subplots(2, 1, sharex=True)
for ax in axes:
df_impact.boxplot(ax=ax)
axes[1].set_yscale("log")
axes[1].set_ylim(bottom=1e3)
fig.supylabel("Affected Population")
Text(0.02, 0.5, 'Affected Population')
Multidimensional Data#
We computed the risk of population being affected by 0.2 m of river flooding from the forecast issued on 2021-07-10 over the next 10 days. We reduced the dimensionality of the data by simply taking the maximum discharge over the lead time of 10 days before computing the flood footprint. We can get a clearer picture of flood timings by defining sub-selection of the lead time and computing footprints for each of these. This is easy to do because we receive the downloaded discharge as xarray DataArray and can manipulate it however we like before putting it into the computation pipeline. However, increasing the amount of flood footprints to compute will also increase the computational cost.
discharge = rf.download_forecast(
countries=countries,
forecast_date="2021-07-10",
system_version="operational", # Version mislabeled
)
discharge
2024-02-29 15:00:44,793 - climada_petals.hazard.rf_glofas.cds_glofas_downloader - INFO - Skipping request for file '/home/roo/climada/data/cds-download/240229-150044-83e84eba8992a4a4d5f8af0a923e2458.grib' because it already exists
<xarray.DataArray 'dis24' (time: 1, number: 50, step: 10, latitude: 95,
longitude: 114)>
dask.array<broadcast_to, shape=(1, 50, 10, 95, 114), dtype=float32, chunksize=(1, 50, 10, 95, 114), chunktype=numpy.ndarray>
Coordinates:
* number (number) int64 1 2 3 4 5 6 7 8 9 ... 42 43 44 45 46 47 48 49 50
* time (time) datetime64[ns] 2021-07-10
* step (step) timedelta64[ns] 1 days 2 days 3 days ... 9 days 10 days
surface float64 ...
* latitude (latitude) float64 55.15 55.05 54.95 54.85 ... 45.95 45.85 45.75
* longitude (longitude) float64 5.85 5.95 6.05 6.15 ... 16.95 17.05 17.15
valid_time (step) datetime64[ns] dask.array<chunksize=(10,), meta=np.ndarray>
Attributes: (12/30)
GRIB_paramId: 240024
GRIB_dataType: pf
GRIB_numberOfPoints: 10830
GRIB_typeOfLevel: surface
GRIB_stepUnits: 1
GRIB_stepType: avg
... ...
GRIB_shortName: dis24
GRIB_totalNumber: 51
GRIB_units: m**3 s**-1
long_name: Mean discharge in the last 24 h...
units: m**3 s**-1
standard_name: unknownimport xarray as xr
discharge_tf = xr.concat(
[
discharge.isel(step=slice(0, 2)).max(dim="step"),
discharge.isel(step=slice(2, 5)).max(dim="step"),
discharge.isel(step=slice(5, 10)).max(dim="step"),
],
dim=pd.Index(["1-2 Days", "3-5 Days", "6-10 Days"], name="Time Frame"),
)
discharge_tf
<xarray.DataArray 'dis24' (Time Frame: 3, time: 1, number: 50, latitude: 95,
longitude: 114)>
dask.array<concatenate, shape=(3, 1, 50, 95, 114), dtype=float32, chunksize=(1, 1, 50, 95, 114), chunktype=numpy.ndarray>
Coordinates:
* number (number) int64 1 2 3 4 5 6 7 8 9 ... 42 43 44 45 46 47 48 49 50
* time (time) datetime64[ns] 2021-07-10
surface float64 ...
* latitude (latitude) float64 55.15 55.05 54.95 54.85 ... 45.95 45.85 45.75
* longitude (longitude) float64 5.85 5.95 6.05 6.15 ... 16.95 17.05 17.15
* Time Frame (Time Frame) object '1-2 Days' '3-5 Days' '6-10 Days'First, we have to clear the cached files to make sure the RiverFloodInundation object is not operating on the last computed results.
Then, we call compute again, this time with a custom data array inserted as discharge.
As additional arguments we add reuse_regridder=True to the parameters of regrid, which will instruct the object to save time by reusing the regridding matrix.
This is possible because all computations in this tutorial operate on the same grid.
rf.clear_cache()
ds_flood_tf = rf.compute(discharge=discharge_tf, regrid_kws=dict(reuse_regridder=True))
save_file(ds_flood_tf, "flood-2021-07-10-tf.nc")
ds_flood_tf
/home/roo/miniforge3/envs/climada_flood/lib/python3.9/site-packages/dask/array/routines.py:325: PerformanceWarning: Increasing number of chunks by factor of 50
intermediate = blockwise(
<xarray.Dataset>
Dimensions: (number: 50, time: 1, Time Frame: 3, longitude: 1356,
latitude: 1128)
Coordinates:
* number (number) int64 1 2 3 4 5 6 7 8 ... 44 45 46 47 48 49 50
* time (time) datetime64[ns] 2021-07-10
surface float64 ...
* Time Frame (Time Frame) <U9 '1-2 Days' '3-5 Days' '6-10 Days'
step timedelta64[ns] ...
* longitude (longitude) float64 5.854 5.863 5.871 ... 17.14 17.15
* latitude (latitude) float64 55.15 55.14 55.13 ... 45.76 45.75
Data variables:
flood_depth (latitude, longitude, Time Frame, time, number) float32 dask.array<chunksize=(762, 162, 3, 1, 50), meta=np.ndarray>
flood_depth_flopros (latitude, longitude, Time Frame, time, number) float32 dask.array<chunksize=(762, 162, 3, 1, 50), meta=np.ndarray>ds_flood_tf.close()
Since the dataset contains more dimensions than latitude, longitude, and the dimension specified as event_dim (here: number), the function hazard_series_from_dataset will return a pandas Series of Hazard objects, with the remaining dimensions as (possibly multidimensional) index.
with xr.open_dataset("flood-2021-07-10-tf.nc", chunks="auto") as ds:
hazard_series = hazard_series_from_dataset(ds, "flood_depth", "number")
hazard_series_flopros = hazard_series_from_dataset(
ds, "flood_depth_flopros", "number"
)
hazard_series
2024-02-29 15:01:35,407 - climada.hazard.base - WARNING - Failed to read values of 'number' as dates. Hazard.event_name will be empty strings
2024-02-29 15:01:37,239 - climada.hazard.base - WARNING - Failed to read values of 'number' as dates. Hazard.event_name will be empty strings
2024-02-29 15:01:38,239 - climada.hazard.base - WARNING - Failed to read values of 'number' as dates. Hazard.event_name will be empty strings
2024-02-29 15:01:39,994 - climada.hazard.base - WARNING - Failed to read values of 'number' as dates. Hazard.event_name will be empty strings
2024-02-29 15:01:40,862 - climada.hazard.base - WARNING - Failed to read values of 'number' as dates. Hazard.event_name will be empty strings
2024-02-29 15:01:41,792 - climada.hazard.base - WARNING - Failed to read values of 'number' as dates. Hazard.event_name will be empty strings
time Time Frame
2021-07-10 1-2 Days <climada.hazard.base.Hazard object at 0x7f10f2...
3-5 Days <climada.hazard.base.Hazard object at 0x7f10f3...
6-10 Days <climada.hazard.base.Hazard object at 0x7f10f3...
dtype: object
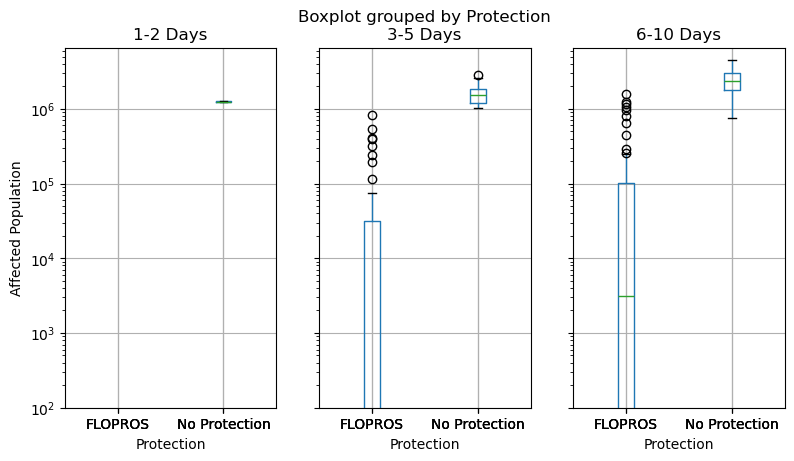
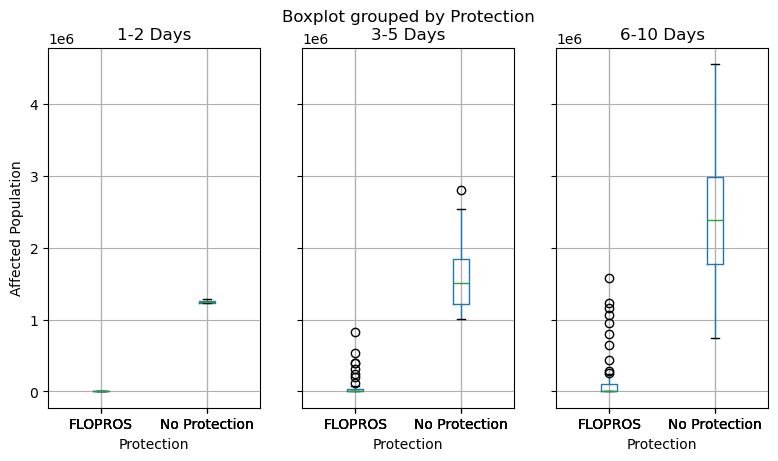
We compute the impacts for all time frames of both series and visualize the resulting distributions with boxplots.
impact_series = pd.Series(
[
ImpactCalc(exposure, impf_set_affected, haz).impact(assign_centroids=False)
for _, haz in hazard_series.items()
],
index=hazard_series.index,
)
impact_series_flopros = pd.Series(
[
ImpactCalc(exposure, impf_set_affected, haz).impact(assign_centroids=False)
for _, haz in hazard_series_flopros.items()
],
index=hazard_series_flopros.index,
)
2024-02-29 15:01:41,831 - climada.engine.impact_calc - INFO - Calculating impact for 2606616 assets (>0) and 50 events.
2024-02-29 15:01:41,991 - climada.engine.impact_calc - INFO - Calculating impact for 2606616 assets (>0) and 50 events.
2024-02-29 15:01:42,161 - climada.engine.impact_calc - INFO - Calculating impact for 2606616 assets (>0) and 50 events.
2024-02-29 15:01:42,339 - climada.engine.impact_calc - INFO - Calculating impact for 2606616 assets (>0) and 50 events.
2024-02-29 15:01:42,434 - climada.engine.impact_calc - INFO - Calculating impact for 2606616 assets (>0) and 50 events.
2024-02-29 15:01:42,541 - climada.engine.impact_calc - INFO - Calculating impact for 2606616 assets (>0) and 50 events.
df_impacts = pd.concat(
[
pd.DataFrame.from_records(
{str_idx: imp.at_event for idx, imp in impact_series.items() for str_idx in idx if isinstance(str_idx, str)}
| {"Protection": "No Protection"}
),
pd.DataFrame.from_records(
{str_idx: imp.at_event for idx, imp in impact_series_flopros.items() for str_idx in idx if isinstance(str_idx, str)}
| {"Protection": "FLOPROS"}
),
]
)
axes = df_impacts.boxplot(
column=["1-2 Days", "3-5 Days", "6-10 Days"],
by="Protection",
figsize=(9, 4.8),
layout=(1, 3),
)
axes[0].set_ylabel("Affected Population")
Text(0, 0.5, 'Affected Population')
axes = df_impacts.boxplot(
column=["1-2 Days", "3-5 Days", "6-10 Days"],
by="Protection",
figsize=(9, 4.8),
layout=(1, 3),
)
axes[0].set_ylabel("Affected Population")
axes[0].set_yscale("log")
axes[0].set_ylim(bottom=1e2)
(100.0, 6561677.47926394)